Can I use this publicly available dataset to build commercial AI software?
By 장학성 |
안녕하세요, 장학성입니다.
AI는 사용하지 않는 기업이 없을 정도로 현대 비즈니스에 중요한 기술이 되었습니다. AI 서비스를 만들기 위해서는 많은 양의 data가 필요한데요, 공개 Datasetpublicly available datasets도 널리 사용되고 있습니다. 다만 공개 Dataset이라고 하더라도 저작권이 있기 때문에 이를 상용 AI 서비스에 사용하려면 저작권 침해 등 법적 리스크를 최소화하기 위해 라이선스 측면의 확인이 필요합니다.
오늘은 이와 관련하여 최근 발표된 논문인 Can I use this publicly available dataset to build commercial AI software?– A Case Study on Publicly Available Image Datasets을 소개하려고 합니다. : https://arxiv.org/abs/2111.02374
“Can I use this publicly available dataset to build commercial AI software? – A Case Study on Publicly Available Image Datasets”
- Gopi Krishnan Rajbahadur, Erika Tuck, Li Zi, Dayi Lin, Boyuan Chen, Zhen Ming (Jack)Jiang, Daniel Morales German
이 글을 통해 공개 Dataset을 활용한 AI 서비스를 준비하면서 저작권 침해를 최소화하기 위해 어떤 노력과 절차를 거쳐야 하는지에 대한 인사이트를 얻을 수 있기를 바랍니다.
1. Intro
이 논문에서는 먼저 공개 Dataset을 사용하기 위한 라이선스는 오픈소스 라이선스와는 달리 몇 가지 어려운 문제가 있다고 설명합니다.
1. 해당 Dataset에 대한 완전하고 정확한 라이선스를 식별하기가 어렵다.
- 예를 들어, Dataset을 제공하던 웹사이트가 폐쇄되는 경우도 있다.
2. 해당 Dataset에 대한 라이선스가 유효한지 확인하는 것이 어렵다.
- 많은 Dataset은 여러 개의 Data Source를 결합하여 생성한다. 이러한 여러 Data Source는 각각 다른 라이선스가 적용된다.
- 더구나 publicly available dataset의 작성자는 Dataset을 만들면서 사용한 다양한 Data Source의 라이선스를 거의 문서화하지 않는다.
- 예를 들어, [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) Dataset도 웹사이트에서 요구하는 유일한 라이선스는 ‘인용 요구' 뿐이고 그 외에는 설명하지 않는다.
- 하지만, [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html)는 상업적 이미지 사용을 제한할 수 있는 라이선스가 적용된 Google Images, Flickr와 같은 다양한 Data Source의 이미지를 크롤링하여 생성되었다.
- 이러한 경우, [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html)의 라이선스만을 고려하는 것은 컴플라이언스 문제가 될 수 있다.
3. Publicly available dataset에 적용된 라이선스는 일반적으로 모호하여 권리와 의무를 명확하게 설명하지 않는다.
- 이러한 Dataset을 사용하여 라이선스 리스크 없이 상용 AI software를 구축하는 것은 실제로 어렵다.
- 예를 들어, GitHub Copilot은 Github에서 호스트되는 수십억 줄의 source code로 training한 대규모 AI Model을 사용한다.
- 그러나 오픈소스 라이선스에서는 소스 코드를 상업적 목적으로 AI Model을 training 하는 데 사용할 권리에 대해 명확하게 정의되지 않았다.
- 이러한 모호성은 GitHub Copilot의 컴플라이언스에 대한 광범위한 법적 논쟁으로 이어졌다.
Copilot은 GitHub에 개발자의 코드 작성을 돕기 위해 공개된 source code를 학습한 AI 서비스이며, 여기에는 Copyleft software도 포함되어 있어서 법적 이슈가 되고 있습니다. 이에 대해 GitHub CEO인 Nat Friedman은 아래와 같이 반박하였는데요,
1. ML system을 training 하기 위한 public data의 사용은 Fair Use이다.
2. ML system에 의한 output은 시스템 operator에게 속한다the output belongs to the operator.
하지만, SFC는 이러한 GitHub의 입장은 Copilot 다음과 같이 사용자에게 큰 피해를 줄 수 있다고 경고하였습니다. 따라서 다른 사람의 저작권을 침해하지 않으려면 Copilot을 사용하지 않는 것이 좋다는 입장을 표명하였습니다.
- “the output belongs to the operator”라는 GitHub의 주장은 잘못된 법적 정당성을 만든다.
- GitHub CEO의 진술은 GPL enforcement action에 직면할 수 있는 Copilot 사용자에 대한 배상 책임을 회피한다.
- 결국 사용자가 Copilot의 output에 대한 ‘Fair Use’ 또는 ‘not copyrightable’하다는 방어책을 마련해야 한다는 말이다.
그러면서, SFC는 Microsoft와 GitHub는 copylefted code로 training 하는 것이 ‘Fair Use’인 이유와 trained model이 “work based on GPL’d software”가 아님을 증명해야 한다고 주장하였습니다.
2. Background
다시 오늘 살펴볼 논문으로 돌아오겠습니다. 논문에서는 Dataset과 관련한 법률 중 저작권법과 계약법에 관해 설명합니다.
저작권법
기본적으로 copyright-protected data는 저작권 소유자가 명시적으로 허용하지 않는 한 상업적으로 사용하거나 배포할 수 없다. publicly available dataset에도 저작권이 있는 data가 포함되었을 수 있다.
- 이를 상업용 AI software를 개발하는 데 사용하면 잠재적으로 저작권 침해가 발생할 수 있다.
- 다만, 특정 상황이나 국가에서는 저작권 소유자의 명시적 허가 없이 상업적 목적을 포함한 다양한 목적으로 저작권 보호 data를 사용하는 것이 허용될 수 있다
- 예를 들어, 미국에서는 최근 소송인 Authors Guild v. Google에서 제안한 바와 같이 저작권 보유자에게 실질적인 피해가 없을 때 Fair Use 원칙에 따라 copyrighted data를 사용하는 것이 허용된다.
- 하지만, 이러한 Fair Use에 대한 판단은 국가마다 다를 수 있다.
- 영국과 캐나다에서는 저작권 침해에 대한 fair dealing exception에 따라 저작권 보유자의 명시적 허가 없이 copyright protected data를 비상업적 목적에 한하여 사용할 수 있다.
- EU에서는 Text and Data Mining Law에 따라 저작권 소유자의 명시적 허가 없이 비상업적 목적으로 copyright-protected material을 사용할 수 있다.
- 이와 같이 상업용 AI software를 구축하기 위해 저작권으로 보호되는 data가 포함된 publicly available datasets를 사용하면 잠재적인 저작권 침해가 발생할 수 있다.
계약법
계약법에 따르면 저작물(예: 이미지, 비디오)의 저작권 소유자는 다른 사람이 향유할 수 있는 권리와 그러한 권리를 향유하기 위해 이행해야 하는 의무를 설명하는 라이선스를 부여할 수 있다.
- 라이선스 조건이 존중되지 않는 경우, 즉 라이선스에 의해 부여되지 않은 권리가 data에 의해 행사되거나 의무가 이행되지 않는 경우 (잠재적) 계약 위반 또는 계약 위반에 해당할 수 있다.
결국 공개 Dataset을 사용하여 AI 서비스를 개발하는 기업은 (Fair Use로 판단할 수 있는 경우를 제외한다면) 저작권침해, 계약법 위반 등을 방지하기 위하여 공개 Dataset과 관련된 권리와 의무를 확인하고 라이선스 컴플라이언스를 보장하기 위한 엄격한 접근 방식이 중요하다고 강조합니다.
그런데 이후에 다시 언급하겠지만 사실 공개 Dataset을 사용하면서 Dataset, Data Source 뿐만 아니라 data point 등의 모든 라이선스를 확인하고 각각의 의무를 준수하는 것은 거의 불가능에 가깝습니다. 공개 Dataset을 사용하기 위해 일정 부분의 라이선스 리스크를 감수하거나 Fair Use라고 주장할 수 있는 법적 근거를 마련하는 것이 현실적인 대응 방안이라고 개인적으로 생각합니다.
그럼 이 논문에서 제안하는 공개 Dataset을 상용 AI 서비스에 활용하기 위한 엄격한 접근 방식이 무엇인지 살펴보겠습니다.
3. Approach
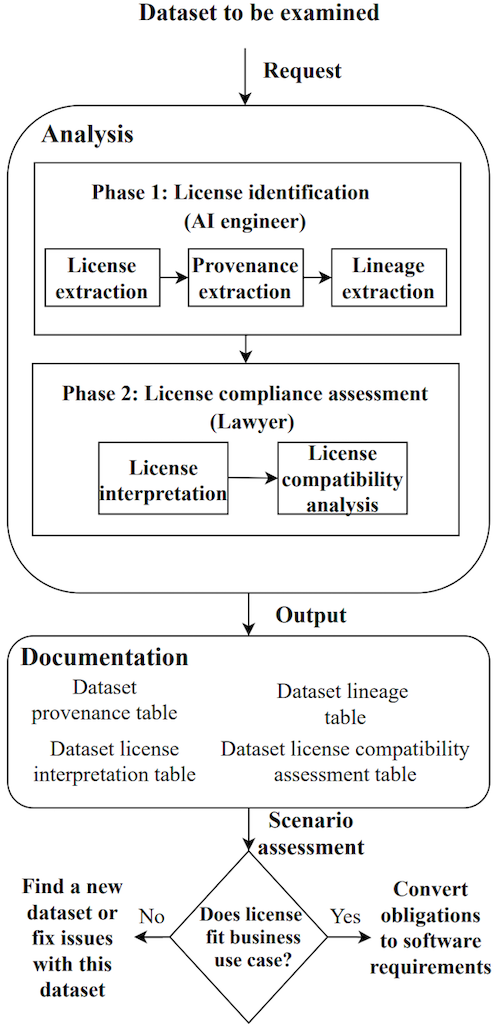
이 논문에서는 공개 Dataset을 사용하려는 AI engieer는 적용된 라이선스를 식별해야 하고, Lawyer는 해당 라이선스의 권리와 의무를 분석하여 상용 AI 서비스에 적용할 수 있는지 판단해야 함을 강조합니다.
먼저, Phase 1은 AI engineer에 의해 라이선스를 확인하는 과정입니다. 논문에서는 자세한 내용을 아래와 같이 설명합니다.
Phase 1 : License identification
#### (Step 1) License extraction
1. AI engineer는 먼저 공개 Dataset을 다운로드한 웹사이트에서 라이선스를 식별한다.
2. 라이선스를 찾을 수 없는 경우 라이선스가 Dataset내에 별도의 파일로 제공되는지 확인한다.
3. 그래도 없으면 Dataset의 소유자에게 연락하여서라도 라이선스를 확인한다.
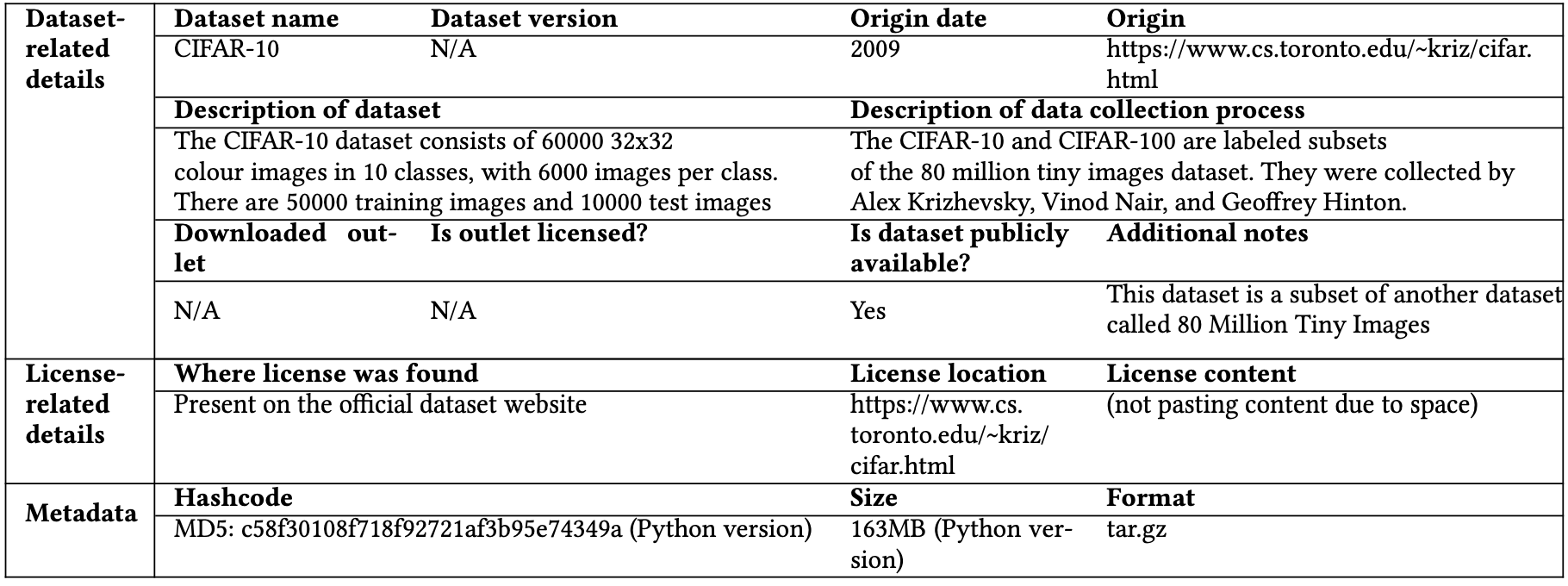
* [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html)를 예로 들면, 웹사이트에 다음과 같이 이 Dataset을 사용하기 위한 조건이 있고, 이를 라이선스라고 간주할 수 있다.
Please cite it if you intend to use this dataset. "Learning Multiple Layers of Features from Tiny Images, Alex Krizhevsky, 2009."
#### (Step 2) Provenance extraction
여기서 Provenance는 Dataset의 원출처를 의미한다.
- 한 연구자가 생성한 Dataset을 누군가 나중에 다른 플랫폼에서도 수정/추가 등 변경 후 배포할 수 있다.
- 따라서, AI engineer는 입수한 Dataset이 원 작성자가 생성한 것과 동일한지 확인하는 것이 중요하다.
- 즉, Step 1단계에서 추출한 라이선스가 Dataset의 올바른 라이선스인지 확인하기 위해 Dataset의 원출처를 확인한다.
1. (Sub-step 1) 우선 적절한 검색어로 검색 엔진에 쿼리하여 Dataset의 공식 출처(예: 공식 웹사이트, 연구 논문 또는 기술 보고서)를 찾는다.
2. (Sub-step 2) 공식 출처에서 라이선스 및 metadata를 추출한다.
* [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html)를 예로 들면, 라이선스 및 원출처에 대한 내용을 다음과 같이 기록해 둘 수 있다.
#### (Step 3) Lineage extraction
컴퓨터 비전 및 NLP Dataset을 포함하여 많은 publicly available dataset은 일반적으로 이미지와 같은 data를 호스팅하거나 인기 있는 웹사이트 등 다양한 소스에서 data를 수집하여 생성된다. 이러한 Data Source의 라이선스는 Dataset의 라이선스와 다르기 때문에 추가로 확인해야 한다.
1. (Sub-step 1) Dataset 생성 프로세스를 추적한다.
- 이를 별도로 기록해둔다. (위 테이블의 “Description of the data collection process” 필드 참조)
- 만약, Data Source 내에 또 다른 Data Source가 있다는 것을 알게 되면 해당 Data Source도 찾아서 기록한다. (재귀적으로 반복)
- 예를 들어, [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html)는 [80 Million Tiny Images](https://groups.csail.mit.edu/vision/TinyImages/)라는 다른 dataset의 subset이다. 논문을 통해 이 Dataset에는 Google, Flickr, Ask, Altavista, Picsearch, Webshots 및 Cydral의 7가지 Data Source가 있다는 것을 알 수 있다.
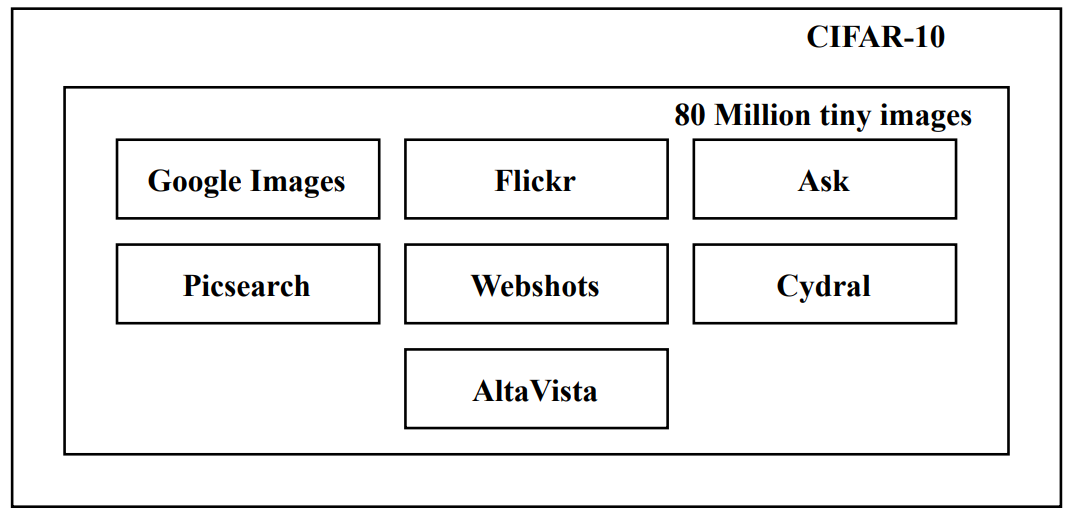
2. (Sub-step 2) Data Source의 공식 출처를 찾는다. (웹사이트, 검색 엔진 등 활용)
- 예를 들어, [80 Million Tiny Images](https://groups.csail.mit.edu/vision/TinyImages/) 웹사이트에서는 Dataset이 더 이상 제공되지 않는다. 이 경우, 가능한 아카이브 버전을 찾는다. (예: [http://web.archive.org/web/20100601000000*/http://groups.csail.mit.edu/vision/TinyImages/](http://web.archive.org/web/20100601000000*/http://groups.csail.mit.edu/vision/TinyImages/))
- 그런 다음, 위에 나열한 7가지 Data Source 각각에 대한 공식 웹사이트를 알아낸다.
3. (Sub-step 3) 시간적으로 적용 가능한 라이선스인지 확인한다.
- Data Source의 라이선스가 시간에 따라 달라졌을 수도 있음을 염두에 둬야 한다.
- 즉, Dataset이 생성된 시점의 Data Source에 대한 라이선스를 확인한다.
- 예를 들어, Google Images에서 온 data인 경우, Google’s Terms of Service from 2005, and/or 2007, and/or 2012 등 중 어느 라이선스가 적용될지 확인한다.
4. (Sub-step 4) Data Source에 대한 라이선스를 식별한다.
- Dataset 생성에 기여한 모든 Data Source와 관련된 라이선스를 식별한다.
여기까지가 Phase 1인데, 공개 Dataset을 사용하려는 AI engineer가 확인해야 할 내용이 적지 않습니다. 더 큰 문제는 아무리 노력을 기울인다고 해도 웹사이트에서 라이선스 정보를 제공하지 않거나, 틀린 정보를 제공한다면 AI engineer가 확인할 수 있는 범위는 제한적일 수 밖에 없을 것입니다. 아뭏든, 논문 내용을 더 살펴보겠습니다. 다음은, Phase 2이며, 변호사 등 법률전문가에 의해 라이선스의 권리와 의무를 확인하는 단계입니다.
Phase 2 : License compliance assessment
#### (Step 1) License interpretation
여기서는 법률전문가가 Dataset과 data의 라이선스를 보고 권리 및 의무를 추출한다.
- 추출된 권리와 의무를 표준 형식으로 문서화한다.
- [Montreal Data License (MDL)](https://arxiv.org/abs/1903.12262) 형식을 보완하여 사용할 것을 제안한다. → Enhanced MDL
- 여기에는 다음 내용을 기록할 수 있다.
1. License metadata
- Licensor
- License name
- Dataset name
- Dataset version
- Credic / Attribution Notice
- License validity period
- Liability / Warranty
- Designated third parties
- Additional condition
2. Data (standalone)
- Rights / Obligations
- Access
- Tagging
- Distribute
- Re-represent
3. Data rights in conjunction with model
- Rights / Obligations
- Benchmark
- Research
- Publish
- Internal Use
- Commercialization
- Output
- Model
- Model Reverse Engineer
#### (Step 2) License compatibility analysis
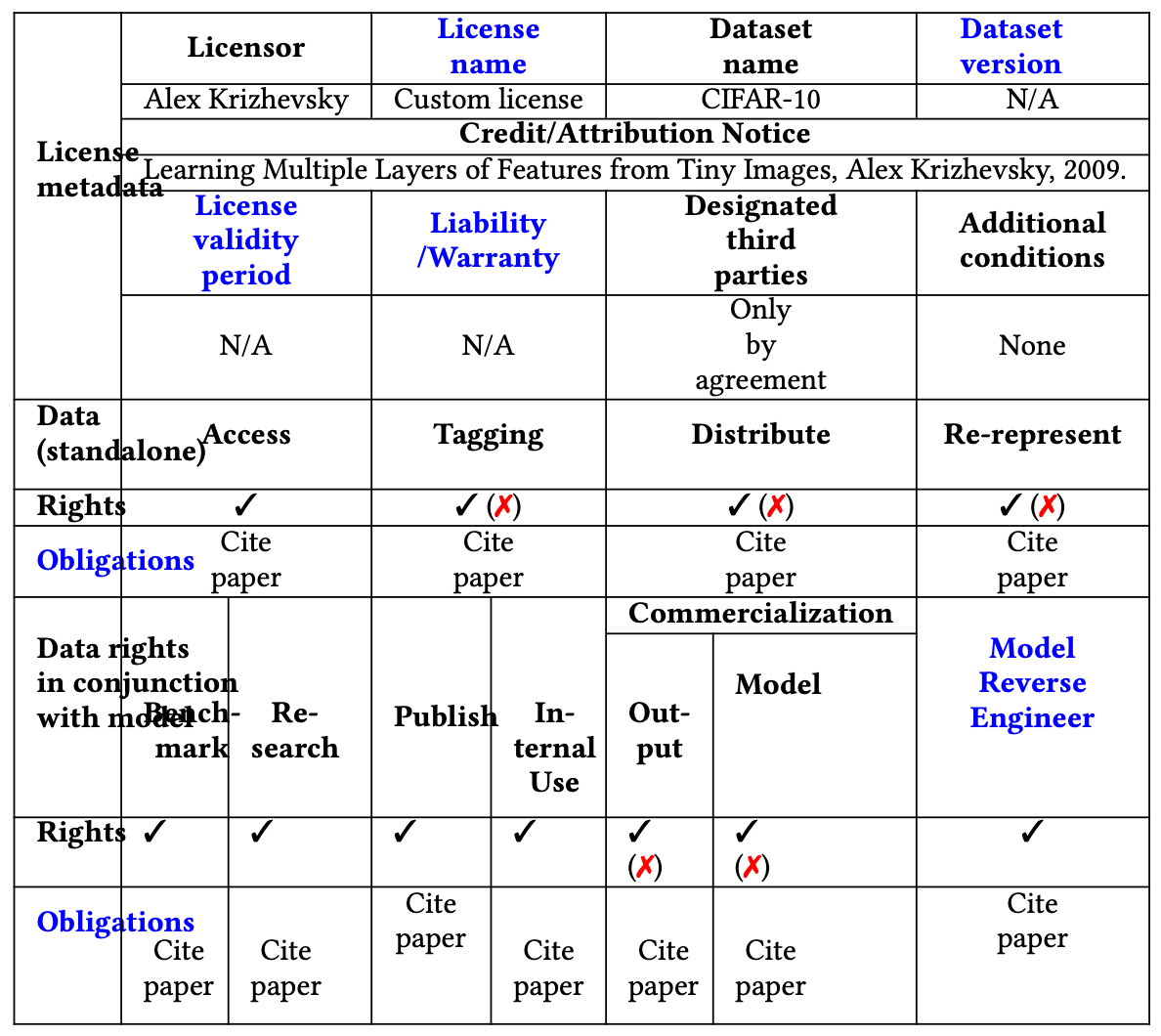
법률전문가는 Enhanced MDL의 정보를 기반으로 위험 평가를 수행하여 dataset을 상업적으로 사용할 수 있는지 결정한다.
- Dataset 라이선스가 허용하더라도 Data Source의 라이선스가 사용 사례를 제한하는 경우에 유의한다.
- 예를 들어, CIFAR-10의 경우 Dataset 라이선스가 허용하는 것과 Data Source 라이선스가 허용하는 것이 서로 다른 경우가 있다.
- 위의 Table에서 빨간색(x)는 Data Source의 라이선스가 제한한다는 것이다. (Google 및 Flickr의 라이선스 등)
요약하자면 CIFAR-10의 라이선스는 논문이 인용되는 한 dataset에 대한 모든 권리를 허용하지만, Data Source의 라이선스는 더 제한적이므로, 이 Dataset을 AI Model을 학습시키거나 또는 Dataset 자체를 수정 또는 배포를 포함한 상업적 목적으로 사용될 경우 라이선스 컴플라이언스 위반의 잠재적 위험이 발생한다.
여기까지 Phase 2를 거치면서 법률 전문가에 의해 Enhanced MDL 포맷으로 라이선스 권리와 의무를 문서화하고 이를 활용하는 방법을 살펴 보았습니다. Dataset 뿐만 아니라 Data Source의 라이선스까지 확인해서 Data Source의 라이선스가 상업적 사용 등 제한을 가하면 Dataset을 상업용으로 사용하는 것도 리스크가 있음을 설명하고 있습니다.
논문에서는 위와 같은 방식으로 다른 Dataset에 대해서도 Case Study를 진행하였습니다. 그 내용을 살펴보겠습니다.
4. Case Study Details
Case Study에서는 인기도와 상업적으로 사용될 가능성이 높은 6개의 이미지 dataset 선택하였다.
1. [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) : Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning Multiple Layers of Features from Tiny Images. Technical Report. University of Toronto.
2. [ImageNet](https://www.image-net.org/) : Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. 2015. Imagenet large scale visual recognition challenge. International journal of computer vision 115 (2015), 211–252
3. [Cityscapes](https://www.cityscapes-dataset.com/) : Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Scharwächter, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. 2015. The Cityscapes Dataset. In Proceedings of the 2015 CVPR Workshop on the Future of Datasets in Vision, Boston, MA, USA, June 11.
4. [FFHQ](https://github.com/NVlabs/ffhq-dataset) : Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4401–4410
5. [VGGFace2](https://paperswithcode.com/dataset/vggface2-1) : Georgia M Kapitsaki, Frederik Kramer, and Nikolaos D Tselikas. 2017. Automating the License Compatibility Process in Open Source Software with SPDX. Journal of Systems and Software 131 (2017), 386–401.
6. [MS COCO](https://cocodataset.org/) : Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In European conference on computer vision. Springer, 740–755.
이 여섯 개 dataset은 모두 이미지에 대한 것이며, 라이선스는 다음과 같은 특징을 갖습니다.
Dataset
Dataset license
Data Source
CIFAR-10
라이선스 언급 없음 (인용만 요구)
Data Source 다수
ImageNet
custom license
Data Source 다수
Cityscapes
custom license
하나의 Data Source
FFHQ
CC-NC-SA-4.0
Data Source 다수
VGGFaces2
CC-NC-SA-4.0
Data Source 다수
MS COCO
CC 4.0
Data Source 다수
그럼 이 논문에서 여섯 개의 dataset에 대하여 연구를 수행한 결과를 살펴보겠습니다.
이미지 Dataset의 가장 일반적인 사용 시나리오는 다음 세 가지로 볼 수 있다.
1. dataset 자체를 상업적으로 배포 (DD : Distribute Datasets)
2. dataset으로 AI Model을 학습하고, 이 모델을 포함하는 임베디드 제품 출시 (RPEAI : Release Product with Embedded AI Model)
3. dataset으로 AI Model을 학습하고, 이 모델 산출물을 상용화 (CAI : Commercialize the Model)
이러한 사용 시나리오에 대한 각 Dataset의 연구 결과는 다음과 같다.
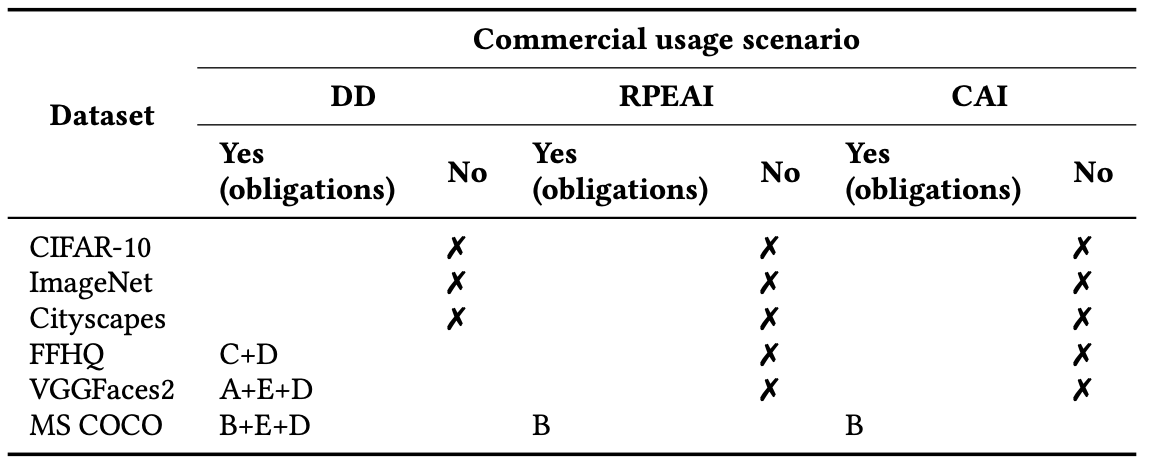
- A - Provide a link to license CC-BY-NC 4.0
- B - Provide a link to the license CC-BY 4.0
- C - Provide a link to license CC-By-NC-SA 4.0
- D - Remove infringing content as soon as possible when an infringement is detected
- E- Indicate changes
### 1. Dataset을 상용 AI software와 함께 배포하는 경우 --> 잠재적인 라이선스 컴플라이언스 위반 초래 가능 (6개 중 3개)
- CIFAR-10, ImageNet 및 CityScapes의 배포는 허용되지 않음
- 이러한 제한에도 불구하고 많은 플랫폼에서 이들 Dataset을 배포하고 있다. (예: [https://deepai.org/datasets](https://deepai.org/datasets) - ImageNet, CIFAR-10 을 배포함) 이는 문제를 유발할 수 있다.
- 다른 3개 Dataset도 동일한 라이선스로 배포해야 해야 하는 등의 의무를 준수해야 사용할 수 있다.
### 2. Dataset을 상용 AI software 학습에 사용하는 경우 --> 잠재적 라이선스 컴플라이언스 위반 초래 가능 (6개 중 5개)
- MS COCO를 제외하고 어느 것도 Dataset을 학습한 AI Model을 상용화할 수 있는 권리를 명시적으로 허용하지 않음
- MS COCO의 경우, Dataset이 상용 AI software를 구축하는 데 사용될 때 다음 사항을 요구함
- 라이선스 링크 제공
- 제품 보증을 위해 dataset를 사용하지 말아야 함
### 3. 6개 중 3개는 Dataset이 수정될 경우 잠재적인 라이선스 컴플라이언스 위반 초래 가능
- AI Model의 성능 향상을 위해 Dataset을 수정하거나 추가하는 경우가 많음
- CIFAR-10, ImageNet 및 Cityscapes의 경우 Dataset을 수정할 경우 잠재적인 라이선스 컴플라이언스 위반이 발생할 수 있음
- 다른 Dataset도 라이선스가 요구하는 대로 정확한 변경 사항을 표시하는 의무를 준수해야 함
이와 같이 Publicly available datasets는 상용 AI software를 구축하는 데 적합하지 않을 수 있다.
논문에서 설명하는 위의 결과만을 보더라도 공개 Dataset을 상용 AI 서비스에 사용하는 것은 잠재적인 라이선스 컴플라이언스 위반을 초래할 가능성이 있습니다. 게다가 논문에서는 이번 연구에서 고려하지 않은 부분이 더 있다고 부연 설명합니다.
5. THREATS TO VALIDITY
### External validity
이 논문에서는 라이선스 위반 측면에 대해서만 연구하였다.
- Dataset을 사용하여 AI Softwae를 구축할 때에는 개인 정보 보호, 윤리적 문제와 같은 요소도 중요하다.
- Dataset을 내부 연구, 학문적 목적으로 사용하는 경우도 다루지 않았다.
- Fair Use, fair dealing, 기타 유사한 법률에 따라 사용할 수 있는지도 다루지 않았다.
- 이 연구에서는 이미지 Dataset에 대해서만 다루었다. video, text 등 다른 Dataset에서는 또 다른 문제가 제기될 수 있기에 추가 연구가 필요하다.
### Internal validity
이 연구에서는 Data Source의 라이선스까지만 고려하고, 개별 data point (예: 개별 이미지)와 관련된 라이선스는 고려하지 않았다.
- 개별 이미지에도 저작권이 있을 수 있다.
- 하지만, 각 Data Source에는 수천, 수만 개의 data point가 있는데, 이에 대한 각 라이선스를 추출하는 것은 사실상 불가능하다.
- 따라서, 이 부분은 여전히 위협으로 남아 있다.
### Construct validity
이 연구에서 확인한 각 Dataset에 대한 provenance나 lineage가 정확하지 않을 수 있다.
- Dataset이 언제, 어디에서 생성되었는지를 정확히 확인하는 것은 불가능하다.
- ImageNet과 같은 경우, 정확한 Data Source를 알 수도 없다.
- 가능한 관련 문서를 통해 Data Source를 유추하여 라이선스를 유추할 수 있도록 최선을 다할 뿐이다.
이럻게 위에서 설명한 data point의 라이선스나 정확하지 않은 정보로 라이선스를 확인할 수 없는 어려움까지 고려한다면 공개 Dataset을 상용 AI 서비스에 라이선스 리스크 없이 사용하는 것은 정말 거의 불가능하다고 봐야 하는 것 아닌가 싶습니다. 그렇다고 AI 제품을 연구하는 데 공개 Dataset을 아예 배제할 수도 없습니다. GitHub가 저작권 침해 이슈가 있음에도 불구하고 Copilot 서비스를 준비하는 것은 일정 부분 법적 리스크를 감수하고, 필요에 따라 법정 다툼도 이어가는 것과 같이 기업이 AI 기술 활용을 위해 어느정도의 잠재적인 저작권 침해 리스크는 부담하는 것도 고려할 필요가 있어 보입니다. 사실, Dataset을 Machine Learning 학습에만 사용하는 것은 저작권 침해에 해당하지 않는다는 견해도 있습니다.
저작권법 제35조의 2에 따르면 ‘저작물을 그 컴퓨터에 일시적으로 복제할 수 있다’고 허용합니다. 이에 따라 Machine Learning training 과정에서 공개 Dataset을 메모리에 일시적으로 복제하는 것도 허용된다고 주장할 여지가 있습니다.
저작권법 제35조의3에서는 저작물의 통상적인 이용 방법과 충돌하지 아니하고 저작자의 정당한 이익을 부당하게 해치지 아니하는 경우 공정 이용에 해당하여 저작물을 이용할 수 있다고 허용합니다. 이미지 정보로 구성된 공개 Dataset을 Machine Learning 학습에만 사용하는 것은 그림이나 사진의 통상적인 이용 방법과 충돌하지 않고, 저작자의 이익을 해치지 않기 때문에 공정이용에 해당한다고 주장할 수 있을 것입니다.
다만, 아직 이에 대한 명확한 판례가 없기 때문에 리스크가 전혀 없다고 할 수는 없습니다. (아참, 저는 법률가가 아니기 때문에 이 내용은 법적인 효력이 전혀 없음을 알려 드립니다. ^^)
유럽, 일본, 미국 등 해외에서는 AI 학습을 위한 빅데이터 이용을 허용하기 위해 법 개정이 되었으며, 우리나라도 이를 위한 저작권법 개정안이 국회에 상정된 것으로 알고 있습니다. 국내 기업들이 공개 Dataset을 보다 수월하게 사용하여 AI 기술 혁신에 박차를 가할 수 있도록 정부에서도 필요한 법안을 신속히 처리해주면 좋겠습니다.